Gata să lansezi AI în producție?
Programează un apel gratuit de 30 de minute cu un inginer AI senior — pleci cu un scop realist, o recomandare de model și o primă estimare.
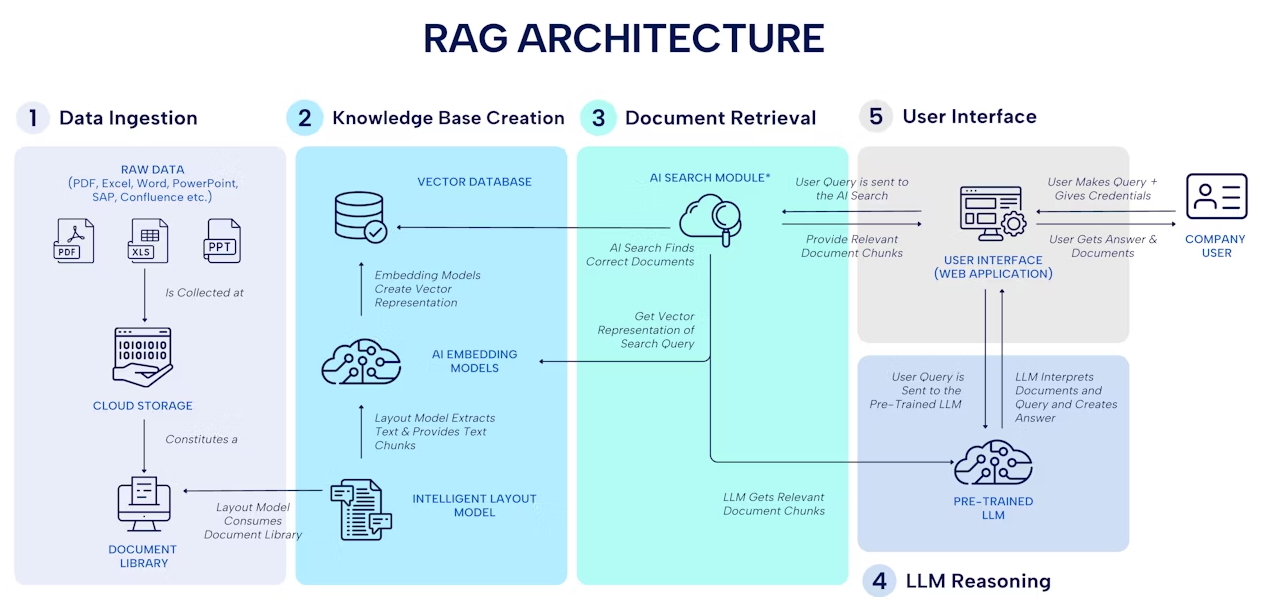
UP2DATE construiește AI de producție — funcționalități LLM, pipeline-uri RAG, agenți AI și automatizare de fluxuri — cu ingineri seniori care dețin calitatea, siguranța și evaluările de la cap la coadă. Nearshore din România, clienți din UE și SUA.

Proiectăm și livrăm funcționalități bazate pe LLM direct în produsul tău — interfețe de chat, sugestii inline, Q&A pe documente și copiloți specializați pe domeniu — cu bugete de latență și cost stabilite de la început.
Sisteme de retrieval-augmented generation care permit modelelor să răspundă precis din date private — ingestie documente, strategie de chunking, selecție embedding și ranking de retrieval, toate în responsabilitatea noastră.
Agenți autonomi multi-pas care declanșează acțiuni, apelează API-uri externe și rutează între instrumente — construiți cu trace-uri observabile astfel încât echipa ta să poată inspecta fiecare decizie a agentului.
Suite sistematice de evaluare, filtre anti-halucinație și dashboarduri de producție care măsoară acuratețea, rata de refuz și costul în timp — stratul de fiabilitate pe care cele mai multe proiecte AI îl omit.
Pregătire de date end to end — curățare, transformare, embedding și indexare în vector stores — astfel încât modelul să aibă întotdeauna context proaspăt și relevant pentru a razona.
O evaluare onestă a situațiilor în care un model personalizat sau un strat fine-tuned depășește un API off-the-shelf — și a celor în care nu. Te ajutăm să investești bugetul AI acolo unde se înmulțește.
Lucrăm cu principalii furnizori de modele și straturi de orchestrare — alegând combinația care atinge țintele tale de acuratețe, latență și cost, nu pe cea care arată cel mai bine într-o prezentare.
Alegerea modelului, strategia de embedding și selecția vector store-ului sunt decizii inginerești, nu preferințe de furnizor. Facem benchmark-uri înainte de a ne angaja și reevaluăm pe măsură ce capabilitățile modelelor evoluează.
Cele mai valoroase ținte sunt de obicei sarcinile repetitive cu informații: revizuirea documentelor, extracția de date, triajul și rutarea, generarea primului draft și Q&A orientat către clienți pe baza cunoștințelor private. Plafonul practic este determinat de câte erori poți tolera și de ce traseu de audit ai nevoie — cartografiem acest lucru pentru fluxurile tale specifice într-o sesiune de discovery înainte de a scrie o linie de cod.
Nu există un singur comutator — este nevoie de apărare în straturi. Combinăm retrieval-augmented generation (ancorarea răspunsurilor în surse citate), scheme de output structurat (limitând ce poate spune modelul), praguri de încredere (rutând răspunsurile cu certitudine scăzută către un om) și o suită continuă de evaluare care măsoară acuratețea factuală față de un set de date de referință. Monitorizarea în producție detectează deriva înainte ca utilizatorii să o observe.
Cumpără pentru sarcini generice unde un produs SaaS acoperă deja 90% din nevoie. Construiește când datele tale sunt proprietare, fluxul de lucru este neobișnuit sau costul per-seat al SaaS-ului depășește un build personalizat în 18 luni. Efectuăm o analiză structurată build vs. cumpărare la începutul fiecărui angajament — dacă răspunsul onest este „cumpără", îți spunem înainte să ne plătești să construim.
Procesăm datele tale în baza unui acord de procesare a datelor aliniat la GDPR. În mod implicit folosim Azure OpenAI sau modele self-hosted, astfel încât datele tale nu antrenează niciodată un model public. Pentru domenii deosebit de sensibile — sănătate, juridic, finanțe — conturăm arhitectura în jurul inferenței on-premises sau VPC-only de la bun început. Politicile de retenție a datelor și controalele de acces sunt documentate înainte ca vreun model să vadă date de producție.
O funcționalitate LLM adăugată punctual — design de prompt, strat de retrieval, evaluări și monitorizare — costă de obicei 20k–60k €. Un flux agentic complet cu instrumente multiple și un strat de trace observabil ajunge la 60k–150k €+. Costurile continue ale modelului (tokeni API sau hosting) depind de volumul de utilizare; le estimăm în faza de scoping pentru a nu exista surprize după lansare. Un discovery call gratuit îți oferă un interval orientativ înainte de orice angajament.
 Automatizare AI
Automatizare AIUn asistent bancar pe GPT-4 antrenat pe peste 50.000 de conversații reale — 24/7, răspunsuri sub 2 secunde în română naturală, cu transfer inteligent către operatori umani.
Programează un apel gratuit de 30 de minute cu un inginer AI senior — pleci cu un scop realist, o recomandare de model și o primă estimare.
Ales de fondatori, scale-up-uri și echipe enterprise

